Query scheduling
Overview
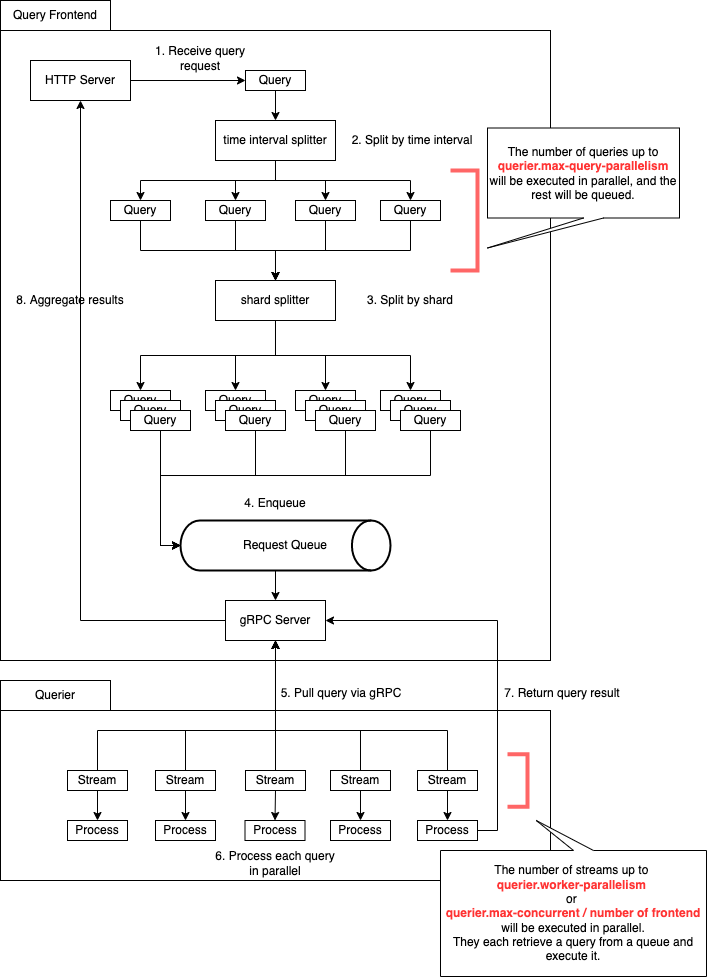
The split queries are enqueued to a request queue by query-frontend.
Some queriers, which are connected to the query-frontend via bidirectional gRPC, get and process them.
In addition, a querier creates a goroutine for each query so that it can handle some queries in parallel.
When the query is completed, it returned the result to the query-frontend via gRPC.
The queued query request has an original query-frontend address so that it can return it to the correct instance.
Here is the overall figure for processing a query.
In conclusion, this architecture has some advantages as listed.
Splitting a query by query-frontend allows queriers to process it in parallel
The query-frontend enqueues queries and queriers pull them from the queue so that queriers can determine when to process queries by themselves.
That's how we can use queriers efficiently.
What is query-scheduler
In 2.4.0 newer version, query-scheduler is released.
This is the component that cuts out the query request queue from query-frontend.
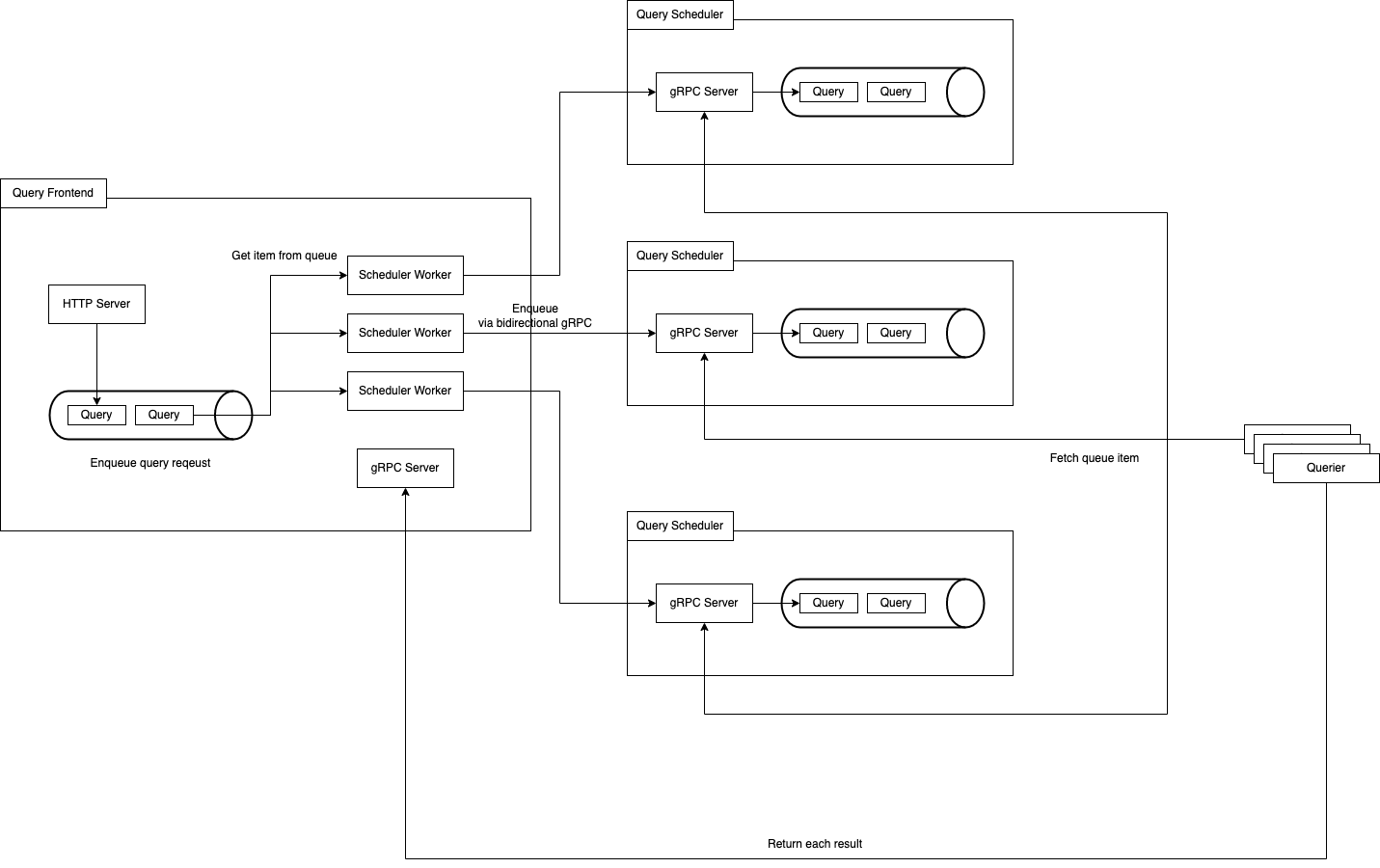
Here is how it works.
Query-schedulers have each request queue.
At first, a query-frontend receives a query request and enqueues it to a request queue.
And then, the request is sent to a query-scheduler and enqueued in that.
All of queriers observe the queues in query-schedulers according to 'query.worker-parallelism' and they get queries from them and process.
That's how a dependency between the query-frontend and querier has gone away.
Why do we need the query-scheduler?
Older architecture has an issue with scaling.
Each querier has the configured number of connections to query-frontends.
It is configured by "querier.worker-parallelism" or "querier.max-concurrent".
It means that query-frontend can't scale more than the parameter.
However, the new architecture with query-scheduler allows us to scale query-frontends regardless of the queriers.
The query-frontend doesn't depend on them anymore.
Last updated