Query Process
Overview
In this chapter, I'll introduce the query process of Loki to you.
You can get the following understandings here.
The components to query
How to split queries
How to schedule query
How to use inverted index
How to aggregate the results from queriers
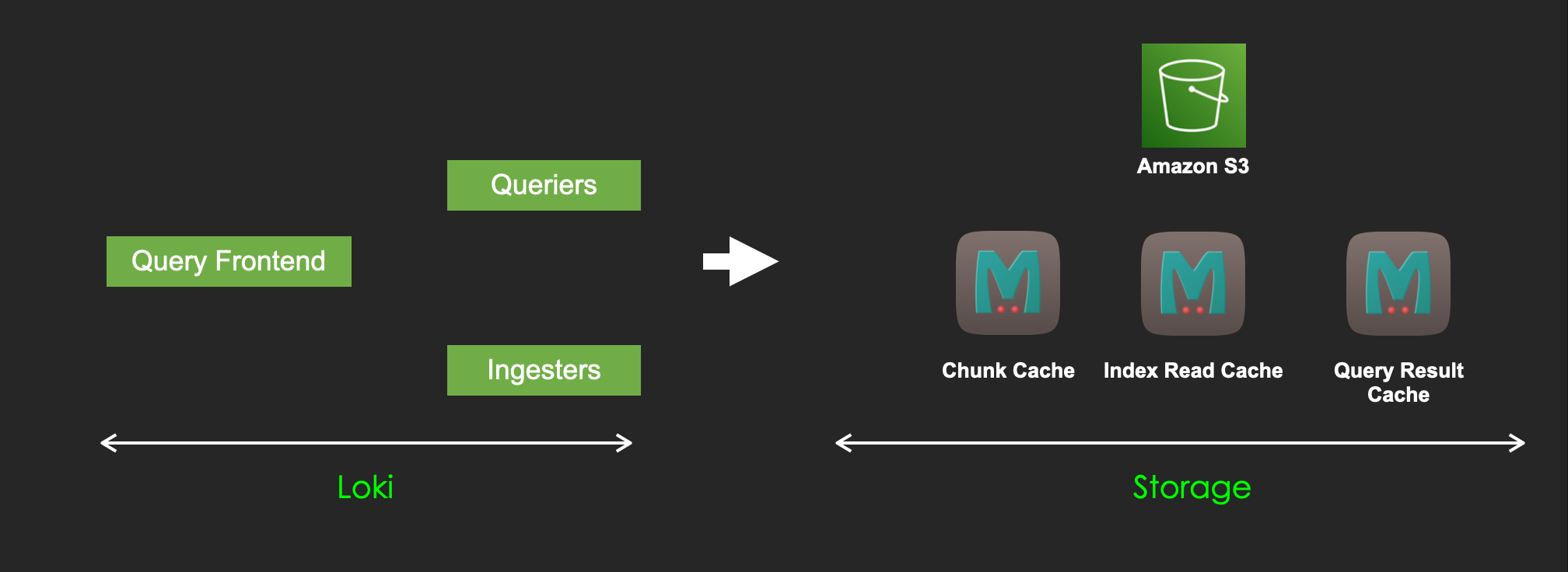
Components for query
Here are the components to query logs.
Ingesters
Ingesters are to be queried for unflushed logs.
Query Frontend
This is an optional component but very important for query performance.
It is a proxy for queriers. Here are its jobs.
It splits queries and schedules them to some queriers and aggregates the results from them
It retries query requests if they fail
It caches query results
It manages rate limit
Especially processing some queries in parallel gives us dramatic improvement in performance.
Querier
Querier is an actual query processor.
AWS S3 as Storage Engine
The logs are stored in this persistently.
This layer also supports Cassandra, GCS, DynamoDB, and other products as storage.
Here are the supported stores.
Memcached as Cache
It is an optional component but very effective for query performance.
There are four types of cache in Loki.
You can know more details about it.
pageCache StrategyRead Path
Here is the "Read Path" in Loki.
A query-frontend receives a query request and splits them into someones
The query-frontend enqueue some queries and some queriers get them from the queue
A querier asks unflushed logs for all of the ingesters
The querier determines the target chunks using inverted indexes in index cache or BoltDB
The querier downloads the target chunks from the chunk cache or AWS S3 and filters them
The query-frontend aggregates all of the results, sorts, removes duplicates, and then returns the result
In further sections, I'll give you more detailed mechanisms.
Last updated