Buffering log chunks on memory in Ingesters
How to handle log post request
Let's see how ingesters handle the requests.
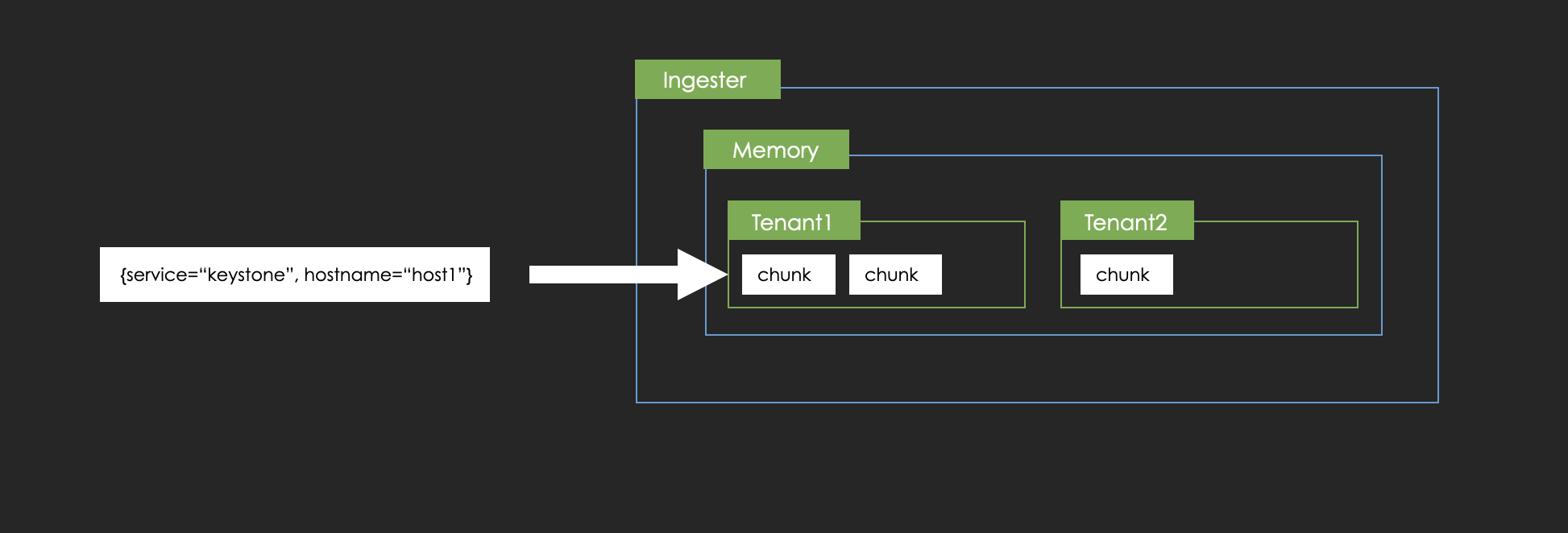
At first, coming logs are appended to "memory chunk" on memory by each stream.
In addition, the write-ahead log for each log is written on Ingester's disk to prevent it from losing log data unexpectedly. (described later)
Lastly, if the appending is succeeded, ingester returns success as gRPC response.
By the way, the chunks aren't stored in remote storage like AWS S3 immediately.
They are buffered unless they satisfy some conditions.
If they satisfy, ingesters will flush them to remote storage.
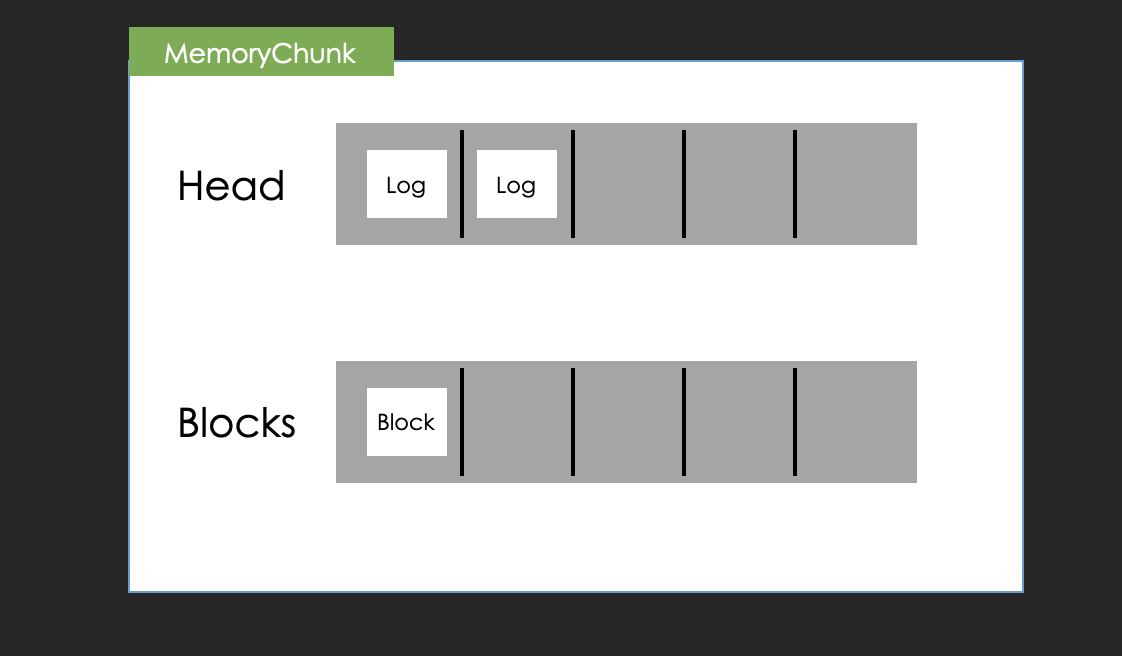
Memory Chunk
The ingesters have a data structure to buffer logs called "memory chunk".
The memory chunk is constructed like this image.
It has two arrays, which are called "Head" and "Blocks".
At first, incoming logs are appended to "Head" with keeping the raw data.
When its size reaches "chunk_block_size", the ingester will compress the all of elements in "Head" into a block and then append it to "Blocks".
The block is encoded as this link.
When the total size of the memory chunk reaches "chunk_target_size", Ingester makes it read-only mode and appends it to a flush queue.
Finally, it is encoded as "chunk format" in this link.
Does buffering logs mean that we can't query for recent logs?
No, it doesn't. Ingesters are also queried for logs from queriers.
So, how does it search all over memory chunks in ingesters efficiently?
The answer is using inverted indexes.
Inverted Index for memory chunks
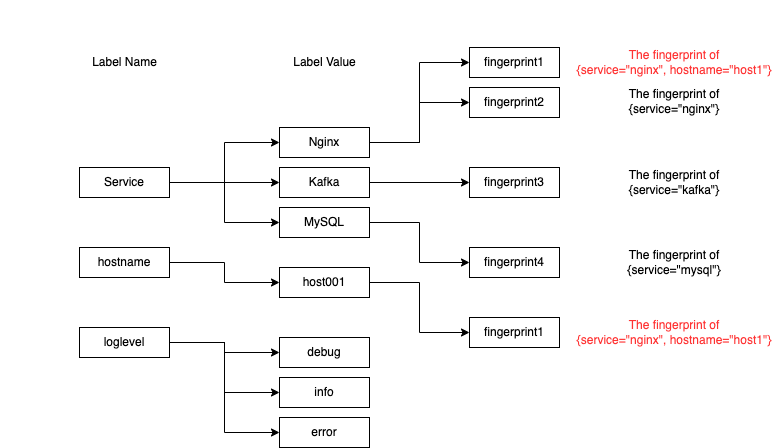
Ingesters have inverted indexes on their memory like the following image.
This is a map structure that maps label key-value pairs to each stream fingerprint.
The label name as the key has a map that has the label values as the keys and stream fingerprint as values.
In other words, it is a nested map structure.
The fingerprints are generated as hash values of label key-value pairs of each stream.
For example, a stream {service="nginx", hostname="host1"}is converted to a fingerprint, which is "fingerprint1" and it is attached to service=nginx and hostname="host1" entries in the map.
In addition, the ingester has also a map that maps fingerprints to actual streams so that it can resolve the streams from the fingerprints.
Here is the flow of how the ingester extracts the matched chunks from memory when querying `{service="nginx", hostname="host1"}`.
Split the query into
{service="nginx"}and{hostname="host1"}Select the matched fingerprints for each label value pair,
{service="nginx"}and{hostname="host1"}. In this case, "fingerprint1" and "fingerprint2" will be matched.Extract common fingerprints across all of them, in this case, it's "fingerprint1".
Resolve the matched streams and chunks on memory from the fingerprints
Last updated