Flushing memory chunks from Ingesters
When the chunks are flushed to AWS S3?
There are main 4 conditions for that.
Reach `chunk_target_size`
`chunk_idle_period` pass after the latest appending
`chunk_max_age` pass after the creation time
Force flush (eg. flush at process shutdown
Of course, they aren't flushed immediately when they match any of the conditions.
They are enqueued to a flush queue and flushed in order.
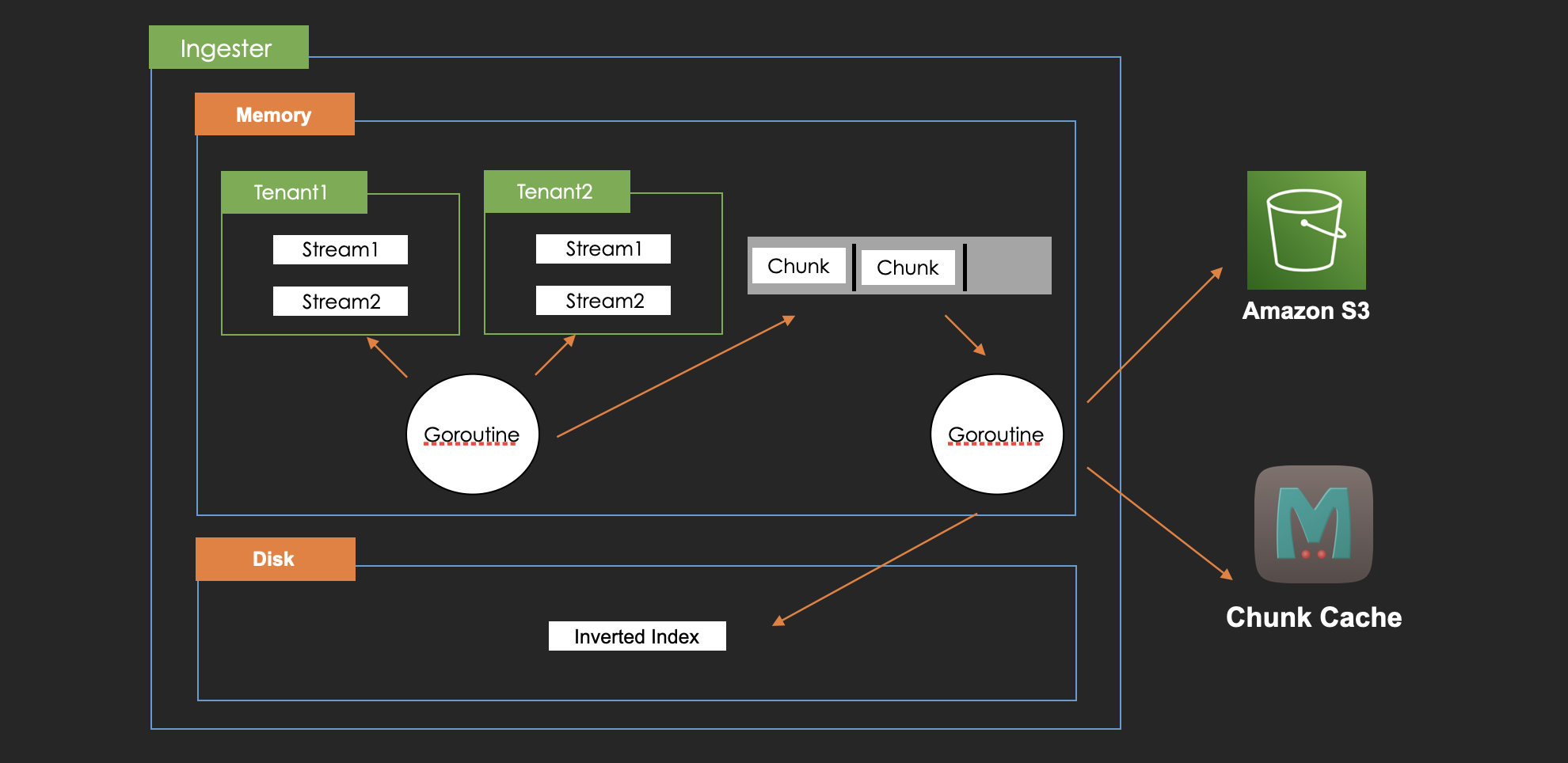
Here is the design for flushing.
A goroutine observes all of the streams on memory and checks if the chunks in each stream match the flush conditions. If some chunks match them, it enqueues them for flushing.
Another goroutine observes the flush queue. It takes a chunk from the queue and flushes it to persistent storage.
There are 3 steps in the flow.
Create an inverted index entry for each chunk and add it to BoltDB on Ingester's disk
Post the chunk to S3
Write it back to chunk cache
By the way, the inverted index here is different from the one for memory chunk which is mentioned in the previous section.
This is described later chapter, Query Process.
Avoid flushing chunks in duplicate
Distributors route logs to multiple ingesters so it can cause chunk duplication.
The ingester doesn't flush a chunk if the chunk is already cached in the chunk cache so that it avoids flushing duplicate chunks.
Of course, this is not enough so queriers and query-frontend try to remove those duplications in query process.
Last updated